Data representation
Patient-level EHR records are summarized into monthly longitudinal data, including demographics, clinical variables, vaccination status, and infection outcomes.
Digital twin microsimulation · Q-learning · Public health policy
A statistical reinforcement learning framework that combines an RNN-based digital twin simulator with tabular Q-learning to develop interpretable public health policies without risky real-world exploration.
Motivation
Public health policy development often faces limited trial data, heterogeneous populations, delayed outcomes, and ethical barriers to online experimentation. This project addresses those challenges by learning policies in a virtual environment calibrated from real-world EHR data.
Method
The proposed framework has three main components: longitudinal EHR data processing, RNN-based digital twin microsimulation, and online tabular Q-learning.
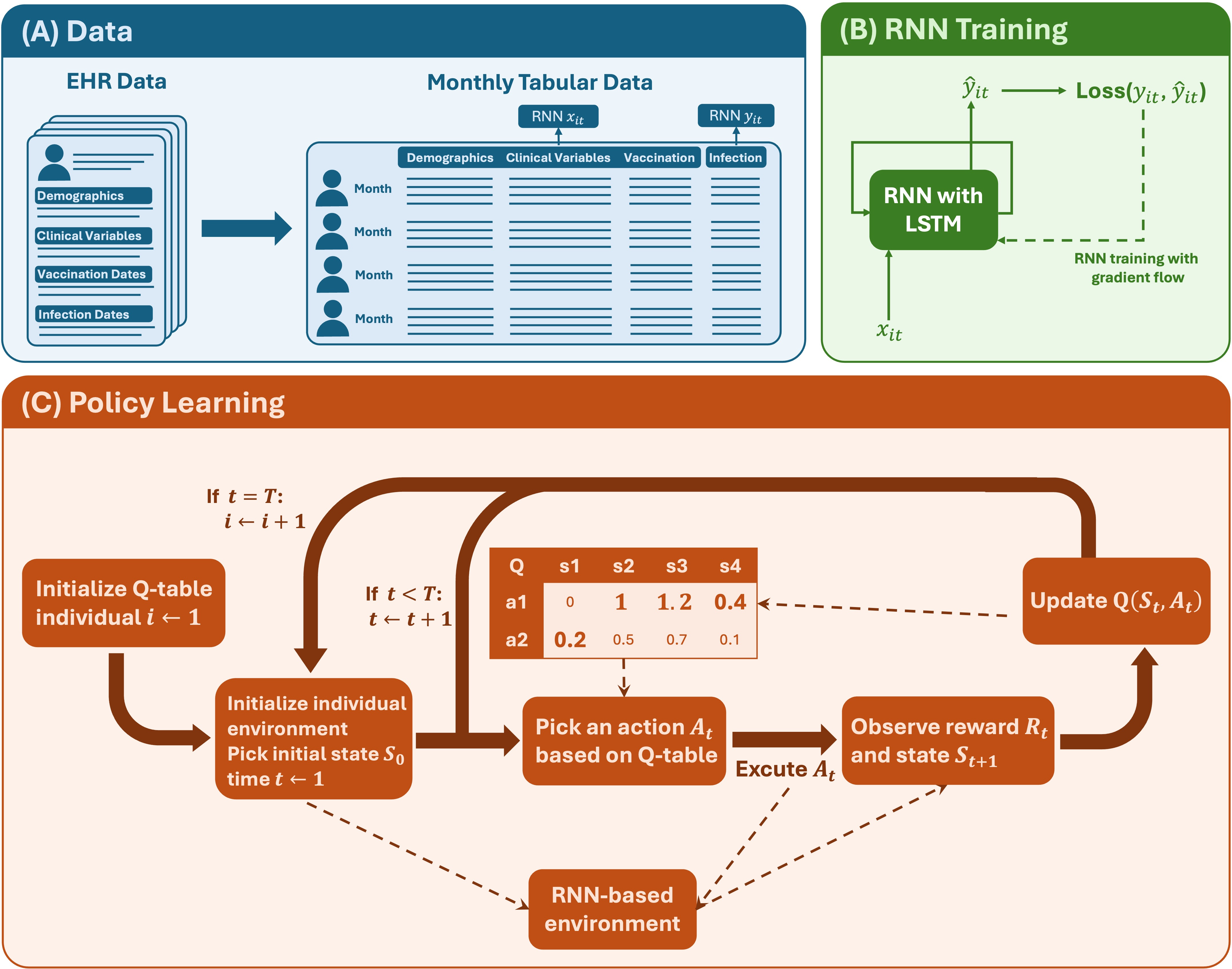
Patient-level EHR records are summarized into monthly longitudinal data, including demographics, clinical variables, vaccination status, and infection outcomes.
An RNN with LSTM architecture approximates transition dynamics and generates virtual patient trajectories for safe policy evaluation.
A discrete Q-table learns when a booster should be recommended, balancing severe infection risk and vaccination cost.
Software
The software and reproducible materials are available on GitHub.
# Clone the repository
git clone https://github.com/kangjian2016/digital-twin-policy-learning.git
cd digital-twin-policy-learning
# Add your environment setup command here
# conda env create -f environment.ymlEnd-to-end walkthrough of the digital twin microsimulation framework, RNN environment construction, and interpretable Q-learning policy development.
The case study evaluates whether digital twin microsimulation can reproduce real-world infection dynamics and whether Q-learning can identify improved, interpretable booster policies.
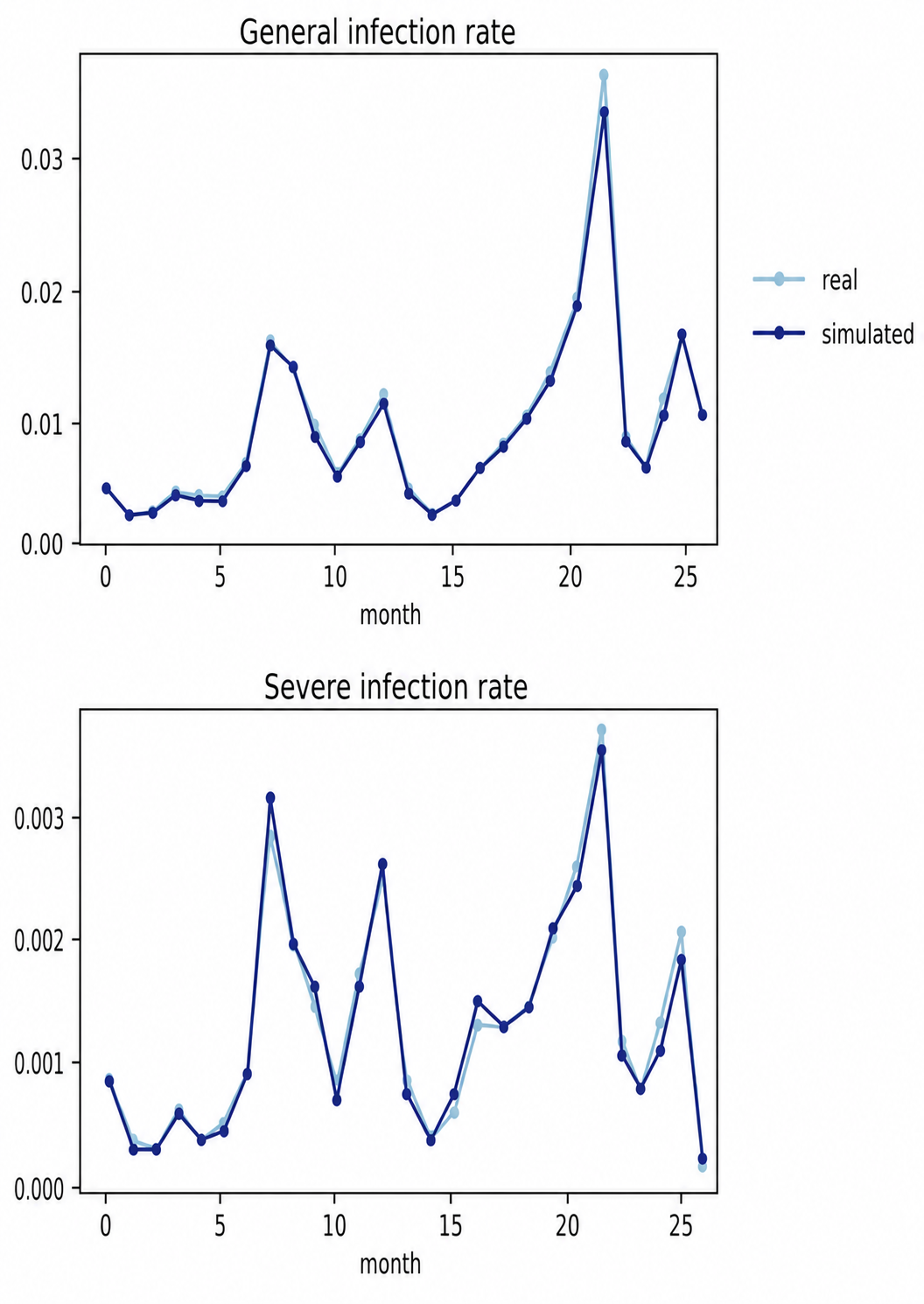
The simulated infection trajectories closely match the observed EHR data for both general and severe COVID-19 infection rates. This supports the use of the RNN-based microsimulator as a realistic virtual environment for policy learning.
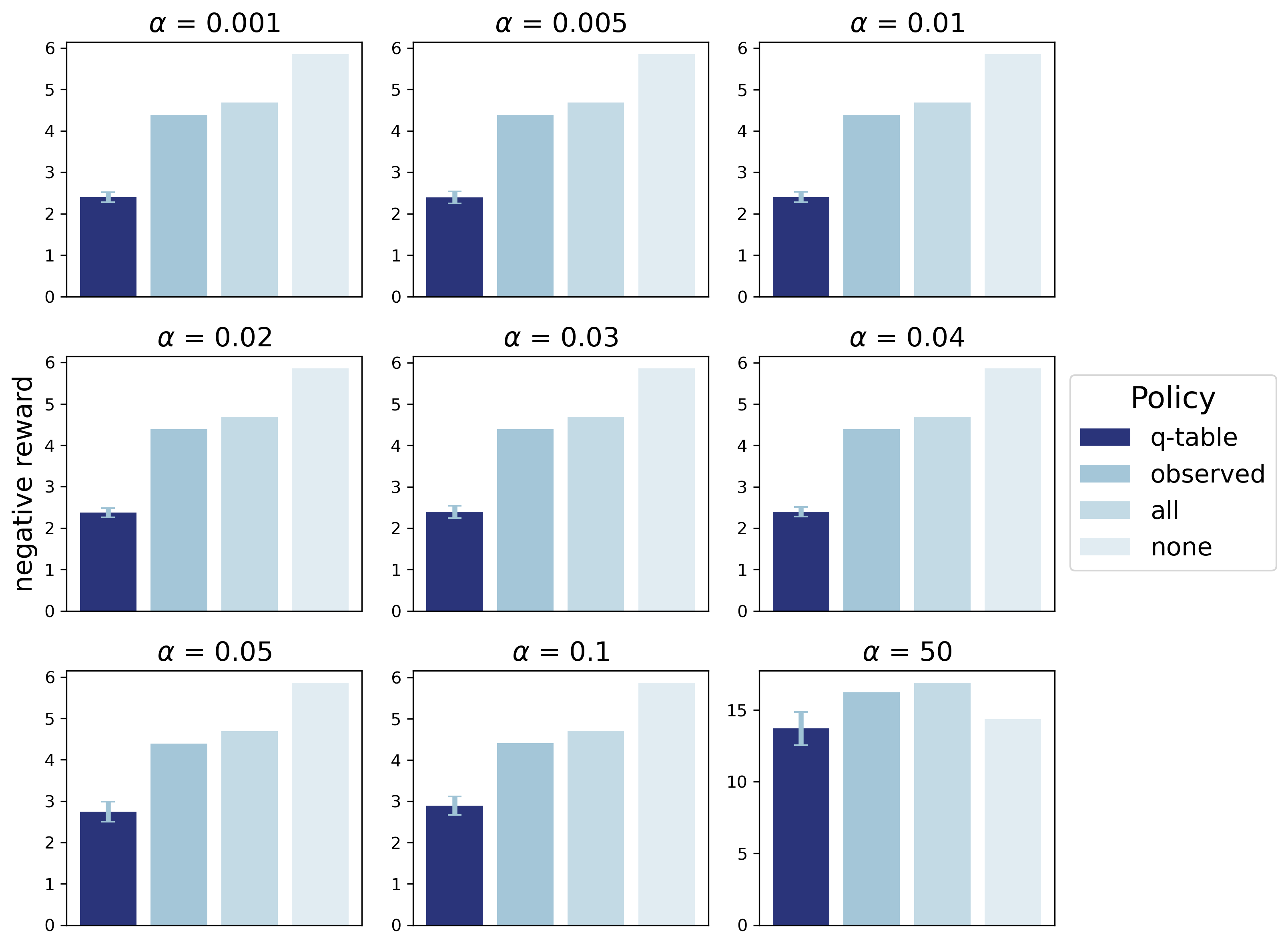
The Q-table policy achieves lower negative reward than observed practice, always-booster, and never-booster strategies across a range of vaccine cost values. This suggests that the learned policy can improve public health decision-making under different risk-benefit tradeoffs.
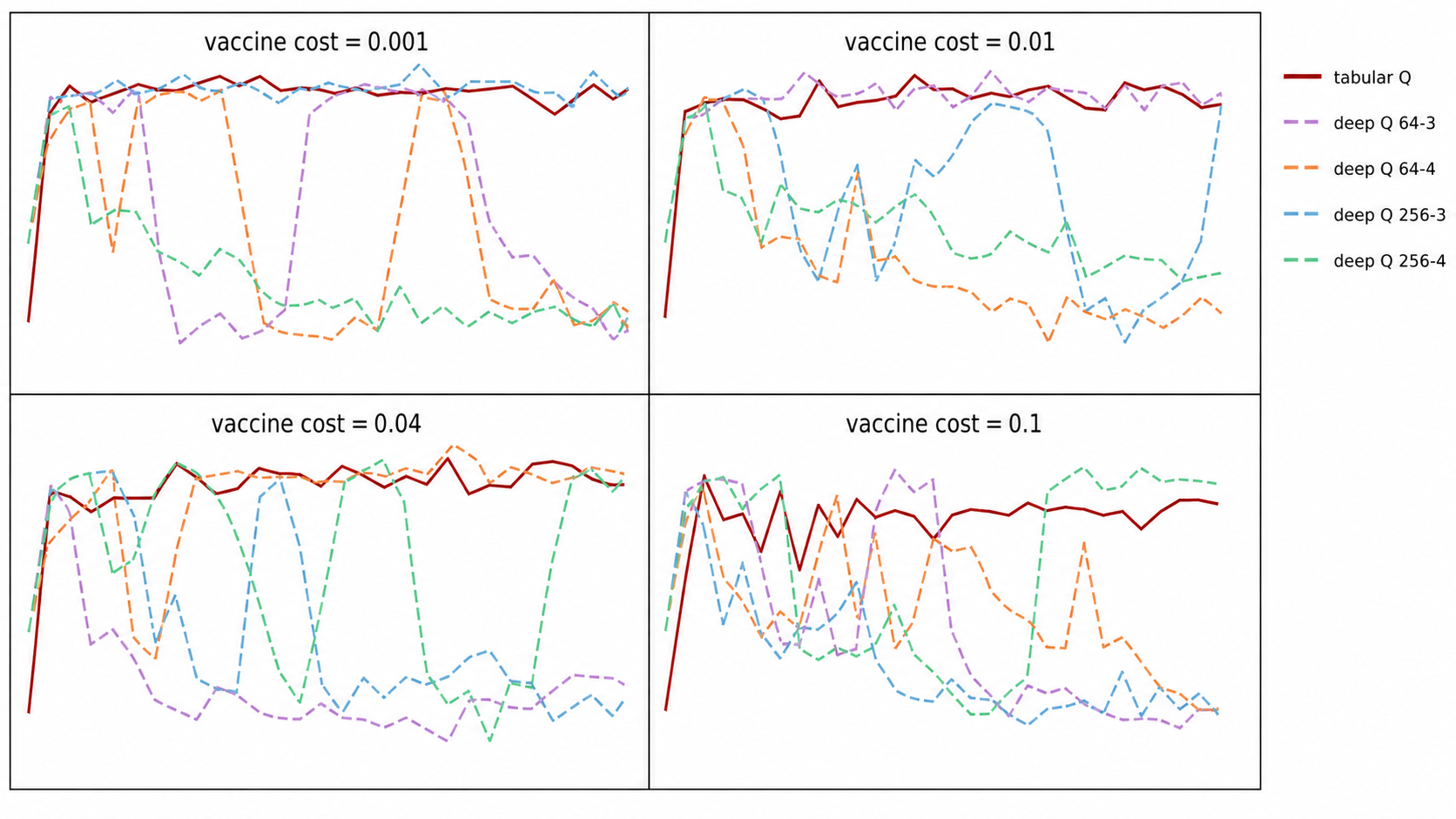
Tabular Q-learning shows stable convergence across vaccine cost settings, while several deep Q-learning architectures exhibit instability. This highlights the practical advantage of interpretable tabular policies when the state and action spaces are discrete and clinically meaningful.
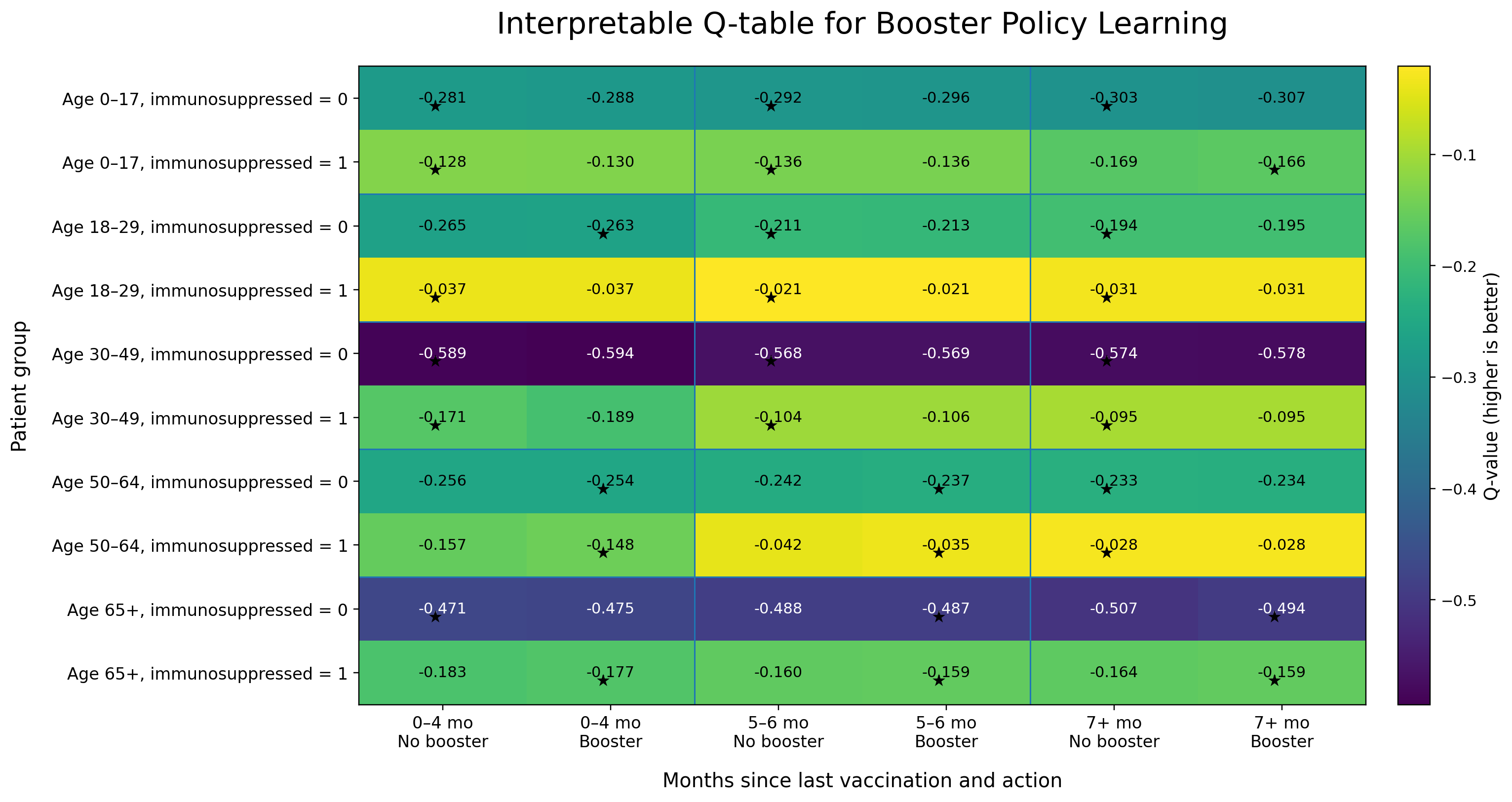
The learned Q-table summarizes the estimated value of each action for clinically relevant patient groups. This makes the resulting policy easier to inspect, communicate, and translate into public health recommendations. ★ indicates the action with the higher Q-value (preferred policy action).
Applications
Policy timing and subgroup prioritization for vaccine rollout.
Sequential decision-making for cancer screening and risk-based monitoring.
Adaptive strategies for interventions such as smoking cessation or disease prevention.
Citation
@article{ma2026digitaltwinpolicy,
title={Development of Public Health Policy by Digital Twin Microsimulation and Q-learning: A COVID-19 Booster Case Study},
author={Ma, Guoxuan and Xie, Sicong and Zhao, Lili and Kang, Jian},
year={2026}
}