HOW TO (start a) SEARCH FOR TRUTH
Eric
Lormand
Draft:
December, 2001
I.� AIMING FOR TRUTH
|
|
����������� Meet longtime Tarot reader and renowned occultist Ren�e
O�Cards. Wracked with guilt over her epistemic irresponsibility, seized with
fear of being deceived by a malignant demon, and prone to escape into sleep
and dreams for unknown time periods, she turns to the consolation of First
Philosophy. Today, in secure possession of leisure in a peaceable
retirement, she opportunely frees her mind from all other cares, is happily
disturbed by no passions, and at length applies herself earnestly and freely
to Seeking Truth. ����������� Unfortunately,
the First Philosophers she meets advise her to accept whatever Method, at
root, is easiest or makes her generally happiest.[1]
She discards such a merely �pragmatic� search, offering her crass
advisors the use
of her old client list, since Tarot readers these days get easy money and a
loving network of Psychic Friends. Her search is to be purely �epistemic�, based singlemindedly
on her aim for Truth. ����������� How should Madame O�Cards � well, she�s discarded her professional name � how should Ren�e proceed? |

II.� AIMING FOR EPISTEMIC
RESPONSIBILITY
|
|
��������������� Ren�e�s
fear of a falsity-insuring malignant demon makes her fantasize about a
truth-insuring benign angel. But perhaps surprisingly, that also scares her!
She aims to find truth, proudly, versus being given it, luckily.
She aims to be responsible for reaching Truth: to develop a set of
sub-aims that she can satisfy, and that lead to satisfaction of her ultimate aim
for Truth. ��������������� The
problem is that any old aim A leads to Truth if an angel rewards those who
aim for A�e.g., by revealing Truth to them on Judgement Day. And any old aim
A precludes Truth if a demon punishes those who aim for A�e.g. by massively
deceiving them. So even if outcome O is necessary for Truth, aiming
for O seems to require betting against demonic punishment for O-aimers. And
even if outcome N necessarily precludes Truth, aiming against N seems to require betting against angelic rewards
for N-aimers. But Ren�e has no evidence against such demons and angels. ��������������� Deep inside Ren�e, however, is
a Nordic defiance of the Fates. She does aim for Truth. But if demons punish
her otherwise rational sub-aims, she�d prefer to sacrifice Truth, and to
reason as if she can satisfy these sub-aims. Nor would she prefer to sell out
her reason to angels promising Truth. How heroic! |

����������� Even
if conditions don�t allow her to be causally responsible for reaching
Truth, Ren�e resolves to reason responsibly. This is a kind of virtual
or representational responsibility: to specify sub‑aims that serve her
end-aims if conditions don�t block her from satisfying the sub-aims.
Specifically epistemic responsibility is reasoning responsibly in this
sense, and doing so based on the sole initial aim for Truth. (Though
Ren�e doesn�t take epistemic responsibility as a means to Truth, her aim
for epistemic responsibility is still �based� on her aim for Truth in a second
sense: her aim for epistemic responsibility depends on the existence of
her aim for Truth. She wouldn�t have an aim for rational responsibility unless
she had the aim for Truth.[5]) (See the rightmost root
of the tree in the
Appendix, Aim 2a.)
����������� Ren�e has a core ground rule for
prideful epistemic responsibility. It constrains her cognitive starting point.
She aims �carefully to avoid precipitancy and prejudice� where she �cannot
exclude all ground of doubt� (see Discourse on the Methods of Rightly
Conducting the Reason, and of Seeking Truth in the Seances; also Aim 2b of
the
Appendix.) I will suppose that with one
kind of exception, Ren�e is unwilling initially to accept contingent
candidate beliefs as (probably or actually) true or (probably or
actually) false. She will not accept such candidate beliefs without
epistemically responsible reasons, and at the start she doesn�t have such
reasons. But as I said there is one kind of exception: beliefs of the form �I
think p� about the contents of her (candidate) beliefs and aims.
Although it is contingent which beliefs and aims Ren�e has�just as it is
contingent whether she even exists�I will assume she correctly forms contingent
self-directed beliefs about them.[6] Also, I will assume she does
correctly sort (candidate) beliefs as necessarily true or as necessarily
false.[7] I will try to show how she
can proceed from there to a justified method of searching for (further)
contingent truths. My hope is that this will eventually point to a way to reach
the same end from a more meager starting point, one without initial reliance on
self‑directed beliefs or beliefs about necessities.
III.� AIMING TO SEARCH
����������� Ren�e
aims to search for Truth. What can she build into this aim, without prejudice
about what�s contingently true? She can stick to necessary parts of
searching in general, independent of the specific Truth-search:
i.e., general facts about searching for food, shelter, justice, peace, love,
hate, war, � even falsity. Then she can remain unprejudiced by applying only
those general necessary parts to her Truth search.
����������� (GX) Generating new candidates for X.
����������� (TX) Scoring generated candidates according to a test for being X.
����������� (AX) Accepting a candidate to the degree it scores highly on the test (absolutely or relative to competing
����������� ����������� candidates).
����������� (HX) Halting if a candidate scores highly enough on the test or if there are no new candidates, otherwise
����������������������� looping to (GX).
A method of
searching for X is a particular means for performing (GX), (TX),
(AX),
and (HX)�including
a generation procedure, a test, a kind of accepting, and threshold scores for
accepting and for halting. (See the leftmost root of the
Appendix tree, Aim
3a.)
����������� (GT)
Generate new candidate beliefs.
In the specific context of (AT),
accepting a candidate belief that p is forming a belief that p.
If the threshold score for halting is higher than that in the previous step for
accepting, Ren�e may form a belief provisionally without halting the search,
and might reject it�destroy it�if another candidate belief scores higher in
subsequent iterations of the search steps. Ren�e�s
test at (TT) may depend on candidate beliefs she accepted
provisionally at a prior (AT) in the same subsearch, or on her
aggregated beliefs from prior subsearches.
IV.� AIMING TO METASEARCH
����������� Though
Ren�e aims to search for Truth, she aims first to search for a method of
searching for Truth. And not just any old method, of course; her aim, ideally,
is to find an ideal method of searching for truth, where what�s ideal is
measured by her aim of finding Truth. Or, failing that, it�s best if she finds
the best method of searching for truth, the method that is closest
to the ideal, where closeness is also measured by her aim of finding Truth. Or,
at least, it would be alright if she finds a right method of searching
for truth, a method that is better than some other candidate methods she will
have considered, and no worse than any others. She aims to mount a �metasearch�
for Truth, which is a search for a right (/best/ideal) method of searching for
Truth.[10]
����������� (GM)
Generate new candidates for a right method of searching for X.
In this case
�accepting� a candidate method is being poised to use the method in searching
for X.[11]
����������� X-Stability:
X remains accepted because its score halts the search or remains higher than
any subsequent
����������������������� competitor�s score.
What�s more, an
ideal search method�with heavy emphasis on �ideal��would meet these X-Specs necessarily,
no matter how the world is. Such a search method would in every possible
circumstance enable one to find X.
����������� Now let�s apply
this in the context of Ren�e�s search for Truth. A metasearch for Truth
contains the following four (repeatable) steps:
����������� (GR)
Generate new candidates for a right method of (sub)searching for Truth.
Judged solely by her
aim of finding Truth, her ideal method of searching for Truth would satisfy the
following three �Truth‑Specs� (special cases of the �X-Specs� listed
above), and would do so necessarily:
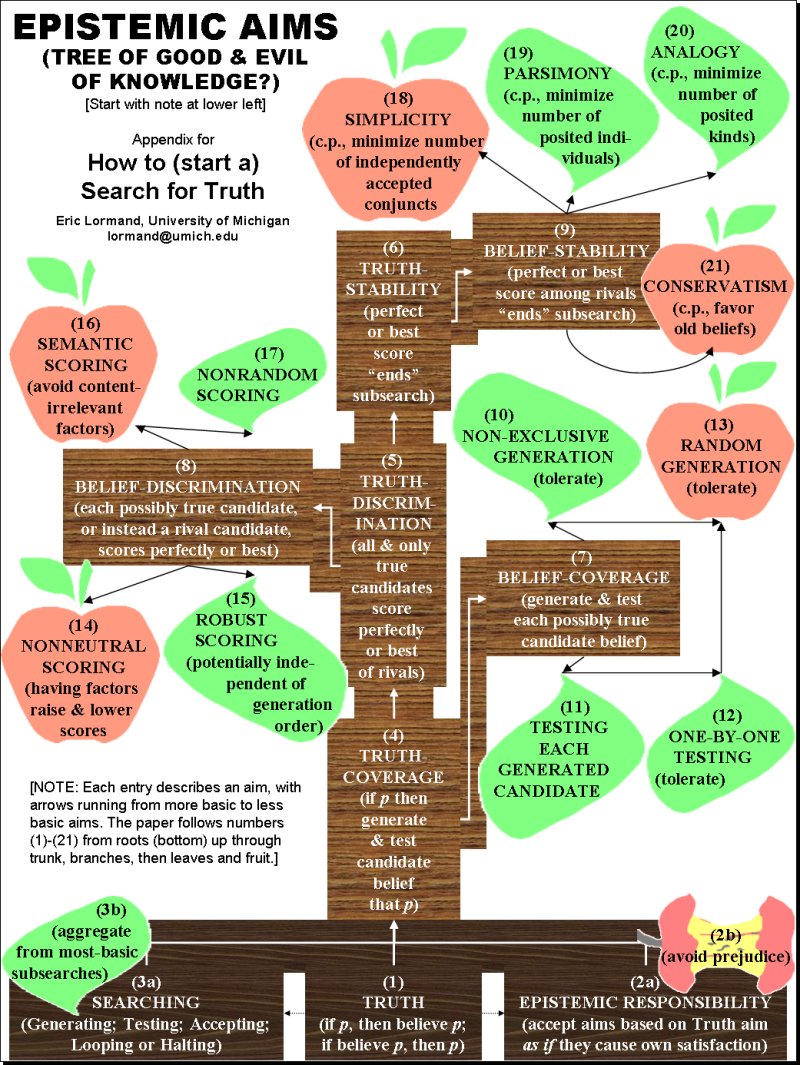
����������� Truth-Coverage: If p,
then a candidate belief that p is generated and tested.
����������� Truth-Discrimination: If
p, then a candidate belief that p scores perfectly or better than
competitors,
����������������������� and so is
accepted.
����������� Truth-Stability: If p, then a
candidate belief that p remains accepted because its score halts the
(sub)search
V.� CARDESIAN FOUNDATIONS
|
|
��������������� Obsessed by her
newfound devotion to philosophical rigor, Ren�e frees up the rest of the
week�not one day less!�for finding an ideal truth‑searching method. On
the second day she reasons that since she�s thinking, she exists. But this
does little to quench her thirst for the whole truth. On the third and fourth
day she argues for the existence of a perfect God (who necessarily protects
her from massive deception)�basically, if there weren�t such a perfect being,
she wouldn�t even have an idea of a perfect being, since she couldn�t have
gotten the idea of perfection from thinking about imperfect things. Over the
next couple days she tries to build a tower toward the truth, the whole
truth, and nothing but the truth, �so help me God�. (For details of this deal
with the divinity, see Meditations on Faust Philosophy.) ��������������� Evening of the sixth day, she sees all that she had made, and, behold, it wasn�t very good. Even given the assumption that she exists and thinks, on second thought she realizes her idea of a perfect being could�ve come from combining ideas of imperfection and of negation, each honed from thinking about imperfect beings. And anyway, she realizes that even a perfect God might deceive her�maybe being massively deceived builds character. Nearly a whole week�s edifice of meditations committed to the flames. |

{kind=link}
����������� Belief-Coverage:
Each possible contingent candidate belief is potentially generated and tested.
����������������������� higher than
any subsequent competitors� scores.
(See the branches of the
Appendix
tree, Aims 7-9.) Does Ren�e have trouble breaking the Circle of Calibration as it
applies to beliefs? She does start out with examples of contingent candidate
beliefs�it doesn�t matter here that she doesn�t start out assuming which of
them are true, and that she doesn�t start out with them as contingent accepted
beliefs. And perhaps she starts out with beliefs about some general features of
contingent candidate beliefs�assuming there are features necessary to
contingent candidate beliefs, which she keys on to distinguish contingent from
noncontingent candidates in the first place. Either way, she may be able to
calibrate candidate methods according to whether they meet the Belief-Specs.
And when beliefs that are covered, discriminated, or stabilized on
happen to be true�even if this is unbeknownst to Ren�e�satisfying these
Belief-Specs satisfies the Truth‑Specs. By carefully clearing out the
issues specifically about Truth, we reach ground upon which Ren�e may be able
to build without prejudice. But there is a little more ground‑clearing to
do.
VI.� AIMING FOR COVERAGE
����������� Ren�e�s aim for
Belief-Coverage is an aim that each possible contingent candidate belief is
potentially generated and tested. Here is how she can use this aim to
assess truth-searching methods with respect to their procedures for generating
candidate beliefs.
VII.� AIMING FOR DISCRIMINATION
����������� Ren�e�s aim for Belief-Discrimination is an aim that some candidate beliefs score perfectly or best among their competitors, while other competitors do not score as high. Here is how she can use this aim to constrain the general features her scoring factors should have. When she is done, she will be in position to start her metasearch.
����������� Ren�e aims to
find nonneutral scoring factors, ones that raise or lower scores of candidate
beliefs. Since the main point of finding factors is to score contingent
candidates, and since she doesn�t start out with any accepted contingent
beliefs (beyond the �I think p� sort):
����������������������� even in the absence of previously
accepted contingent candidates.
She can also apply her structural aims for ideal generation and
scoring as follows:
����������������������� even in the absence of previously accepted
scoring factors.
These general features provide ways to score candidate scoring
factors.
IX.� AIMING FOR STABILITY
����������� Ren�e�s aim for
Belief-Stability is an aim that at some point a perfect or best
(discriminating) score for a candidate belief halts the (sub)search, or remains
higher than any subsequent competitor�s score. Here is how she can use
this aim to give purely epistemic (provisional) support to some more-or-less
familiar candidate virtues often considered to be merely pragmatically
supportable, at best.
SIMPLICITY (Aim 18)
����������� Step
One
(Generating): By definition, a (candidate)
belief that p is �committed� to particular contingent entities or kinds
of entities E such that, necessarily, E exists if p. Ren�e might
responsibly satisfy her aim for semantic relevance by considering amount of
such commitments as scoring factors.[24] Also, a belief (or group
of beliefs) has greater �parsimony� the fewer particular entities it is
committed to.[25]
And the fewer kinds of entities a belief (group) is committed to, the
greater �analogy� it exemplifies�the more similar to one another are the
particular entities it is committed to.
����������� Step
Two
(Minimal Testing): Parsimony is provisionally
acceptable as a virtue for reasons similar to simplicity. Raising the scores of less parsimonious
competitors precludes stabilizing (since there is always a way to �multiply
entities� further) unless Ren�e gets lucky. So ParsimonyVirtue wins.
In the same way, rewarding candidates for positing more �kinds� of entities,
laws, or processes (etc.) is also a never‑stabilizing method (barring
luck). So (provisionally) the more analogous to one another the posited
entities, laws, or processes, the better.[26]
X.� PROSPECTS FOR REN�E�S SEARCH
����������� I leave open which other scoring
factors, if any, Ren�e can provisionally accept, prior to her search for
contingent truths. These depend on her ingenuity (if any) in generating
candidate factors (subject to constraints such as semantic relevance), on the
impact (if any) of Coverage and Discrimination as well as Stability, and on the
existence of further Specs (if any) derivable from her root aims. But since
ideas for such elaborations are scarce, I will end by illustrating how Ren�e�s
search might proceed given what has been supported so far.
����������� Simplicity, conservatism, and kin
are typically cast as criteria to be used in inference to the best explanation.
But they are supportable independently of aims for explanation. Ren�e
can treat them as criteria to be used in inference to best beliefs,
whether or not these have �explanatory power�. If explanatory power is a virtue
at all, perhaps it is a merely contingent virtue (to be supported as Ren�e aggregates
contingent truths).
CANDIDATE BELIEFS AS DATA
����������� Ren�e avoids prejudice by avoid
prejudging contingencies beyond self-directed �I think p� beliefs. She
can start with beliefs about necessities and possibilities, and self-directed
beliefs about these beliefs. But where p is contingent (and not itself
of the form �I think q�), Ren�e doesn�t initially form the belief that
p and so doesn�t initially form the belief that she believes p.
However, she may without prejudice initially form the candidate belief that
p, and so the genuine belief that she has a candidate belief that
p. Ultimately, this is her only source of �data�.
����������� Ren�e�s epistemic reasoning is
filled with evaluations, beliefs about which candidate aims and beliefs she should
accept. But these are all hypothetical evaluations, evaluations made
true in part by her basic aim for Truth. From her starting point, without
prejudice, can she reach justified categorical evaluative beliefs,
evaluative beliefs that are true no matter what aims are in place? If
Ren�e�s only data are her beliefs about which candidate beliefs she has, then
she has no categorical evaluative beliefs as data (even if some of her
candidate beliefs are themselves categorically evaluative).[30]
Perhaps categorical evaluative beliefs can help explain (or at least unify) her
nonevaluative beliefs about which candidate beliefs she has, but at the moment
Ren�e can�t think of how they might (or how they might do so better than
nonevaluative competitors). So suppose she has no �data� relevant to justifying
categorical evaluative beliefs.
����������� It might appear that she is stuck.
But this is one place where it matters that her provisional method is that of
general inference to the best beliefs rather than specific inference to
the best explanation. Her aim isn�t for accepting the most
virtuous available belief that might explain or unify data. It�s to accept the
most virtuous available belief, period. If no candidate evaluative
beliefs unify any data, they are all in effect tied at unifying zero
data, so this �other thing� is �equal� and the candidates can be scored using
the other factors. Of competing categorical evaluative beliefs that equally
explain nothing, she should accept the simplest (or most parsimonious or
analogous).
����������� (A)
Ideally, every aim should be satisfied.
����������� (B)
Ideally, some aims should be satisfied and others should be frustrated.
����������� (C) Ideally, every aim should be
frustrated.
Candidates (A) and
(C) seem simpler than candidate (B), but equally simple to one another.
However, (C) seems to harbor a paradox in a way that (A) does not. If that air
of paradox can be spun into a reason to reject (C), then (A) is supported.
����������� (A1)
Each aim should be satisfied (so in the aggregate, all should be).
����������� (A2)
Some aims should be satisfied, others are neutral (so the aggregate goes above
and beyond �duty�).
����������� (A3) Only the totality of
aims should be satisfied (so the ideal is all-or-nothing).
(A1) is simpler than
(A2) and (A3), in not drawing distinctions among aims. It also explains (A) in
a way that is most analogous to the way basic universal facts are explained in
the nonevaluative realm. The totality of mass is subject to gravity because
each bit of mass is subject to gravity, not because gravitation is partial or
all-or-nothing.[31]
[1]
E.g., Quine: �[T]he considerations which guide [one] in warping [one�s]
scientific heritage to fit [one�s] continuing sensory promptings are, where
rational, pragmatic� (�Two Dogmas of Empiricism�, p. 46). Or Lycan: �[O]
[2] Or
true judgments, thoughts, theories, hypotheses, perceptions, etc. For brevity,
I will typically use the example of beliefs as a stand‑in for any mental
candidate for truth, positioned for use in ways aimed at taking advantage of
its truth. (Renee would also aim to form true discourse she is poised to
use, if she were to believe she has a community and a communicative language.)
[3]
And what kind of �aim� does Ren�e have for truth (or other targets to be
discussed)? We can construe Ren�e�s aimings as desirings, and I will
typically write this way for familiarity�s sake, though I doubt that this would
survive in a stricter treatment. Here are some of the twists (which can be
skipped).
��������������� An aiming can be a (mental)
representation of its target X�as with desiring X, or evaluatively
believing that X is (say) good. Or it can stand in a nonrepresentational
relation to its target X�as with having a function to bring about X without
having an idea of X (and so without having desires or beliefs about X).
Something�s having a function can be a matter of its past�in the simplest case,
being copied from certain ancestors that reproduced, despite obstacles, because
they brought about (past analogs of) X. Or it can be a matter of current
organization�in the simplest case, forming certain larger wholes, despite
obstacles, by bringing about X.
��������������� What all these kinds of aimings
have distinctively in common is quite abstract, so it�s hard to say whether the
list of kinds should be expanded, or how these blurry gestures at the kinds
should be sharpened, or in the end what should be a criterion for being an
aiming. I would try to understand aimings generally in terms of how they reduce
�teleological� accounts of entities to �constructive� causal or mereological
explanations.
��������������� If Ren�e�s aimings are
evaluative beliefs about truth, then they could be products of malignant-demon
deception. Maybe truth isn�t good. Similarly, if her aimings are desires
for truth, they are partly constituted by ideas of truth, which might be
composed of certain beliefs about what truth is (or would be). And these
beliefs might likewise be products of demonic deception. The function option
(whether historical or organizational) insulates her most from the demon.
[4] One may be poised to use a belief to various degrees, when an opportunity arises. Ren�e�s aiming allows for the possibility that her beliefs differ gradually in this respect. To whatever extent Ren�e is capable of less than full degrees of belief (or disbelief), this yields another respect in which her aims are partially satisfiable. Ideally she�d fully strongly believe what�s true and fully strongly disbelieve what�s false, but failing that, her aims are more satisfied the stronger her belief in what�s true and the weaker her belief in what�s false. Nothing here assumes that there is more than one degree of strength for beliefs, or that there are precise quantitative rather than rough qualitative strengths, or that there is only a single dimension along which the strength of a belief varies. It�s just that Ren�e aims her search flexibly to cover any such alleged possibilities.
[5] Together the two aims help
comprise her aim of finding Truth, but this doesn�t point to some more
general aim from which Ren�e derives her aim for rational responsibility. We
can even suppose she wouldn�t aim for finding anything if she didn�t aim
for finding Truth, even if she would aim for having other things. If she
were to be disturbed by a passion for some candy, or some friendship, for
example, she wouldn�t mind luckily being given that by a benign angel.
[6]
However, to make �I think p� beliefs her only unprejudiced
contingent beliefs, we have to add the proviso that Ren�e�s self‑directed
beliefs don�t entail�or aren�t treated as entailing�a
wider range of contingencies (beliefs that are both possibly true and possibly
false). So if beliefs or aims have contents with Putnamian �wide�
aspects (e.g., demonstrative or indexical aspects) that do not reduce to
�narrow� descriptive or self-referential aspects, Ren�e may not start with
beliefs about such wide aspects. We assume she only knows �narrow� aspects of
the contents of her beliefs and aims. With that said, I don�t think anything below
turns on the nuances of �wide� versus �narrow� content. Nor will anything turn
on an assumption of omniscience about her beliefs and aims. First, we won�t
need to assume that she automatically forms self-directed beliefs about every
thought (which would lead to an infinite nesting of such beliefs � �I think I
think � I think p�) but only that she forms such a belief when she
considers whether she has a particular thought. Second, we won�t need to assume
that Ren�e has any more insight into her beliefs and aims than you or I
effortlessly have into many of our own.
[7] However, as in the previous note we have to add the proviso that her beliefs about necessity and possibility don�t entail�or aren�t treated as entailing�any forbidden fruit among prejudiced contingent beliefs. Roughly, if there are Kripkean �a posteriori necessities��necessary truths that are only rationally believable given other contingent beliefs�Ren�e may not start with those. But this is only rough, because Ren�e might be permitted to begin with beliefs in certain a posteriori necessities, if the only contingent beliefs these depend on are the permitted self-directed ones. With this said, as before, I don�t think anything below turns on the nuances of �a posteriori� versus �a priori� necessities. Nor will anything turn on an assumption of omniscience about necessities and possibilities. First, we won�t need to assume that she automatically forms beliefs about every necessity and possibility, but only that she forms such a belief when she considers whether something in particular is necessary or possible. Second, we won�t need to assume that Ren�e has any more insight into necessities and possibilities than you or I effortlessly do.
[8]
She does not need to establish an additional test for whether her aggregation
is complete. No aggregation of beliefs is complete unless it contains a belief
that it is complete (to cover the truth that it is complete). And a test for
truth that applies to such a belief would be a test for completeness. So
Ren�e only needs to establish a test for truth in general, one that can apply
to groups with or without a completeness belief.
[9] In this and subsequent descriptions of search steps, italicized words are variations on, and ellipses stand for unchanged material from, prior descriptions of search steps (at root, the general search-for-X rubric above).
[10]
Ren�e has no need for a metametasearch�a search for a right (/best/ideal)
method of metasearching for Truth�because her basic aim for Truth itself
establishes a right (/best/ideal) method of metasearching. In her metasearch,
she should score search methods according to how well they promote her root aim
for Truth (or how well they do if she executes them, given her aim for
epistemic responsibility).
[11]
This note details what forms a mere candidate method might take, and ends with
an observation about measuring the �feasibility� of candidate methods. Neither
matter is needed for understanding the remainder of the paper.
��������������� Prior to acceptance, candidate
methods can be generated in at least two forms, �offline� and �virtual�.
Respectively, these give offline and virtual scores to candidates for X.
��������������� Offline candidate methods are
truncated versions of accepted candidate methods: processes that, like
accepted methods, generate candidates for X and score them. But unlike accepted
methods these merely offline scores do not cause or constitute acceptance (or
rejection) of the candidates for X. Accepting an offline candidate
method is putting its offline scores �online�, having the scores it gives to
candidates cause (or constitute) acceptance of the candidates for X.
��������������� Virtual candidate methods are representations
of the processes that (would) comprise a method (if accepted). Such virtual
methods might be candidate representational aims to accept the processes, or
they might be accepted beliefs about how the processes work. Unlike accepted
methods or offline methods, these representations do not directly generate
candidates for X. Instead they merely generate virtual candidates for X�representations
of candidates for X. Using these they generate virtual
scores�representations of scores�for candidates for X. Accepting a virtual
candidate method is making its virtual scores �come true�, having the virtual
scores it gives using virtual candidates for X cause acceptance of the
represented candidates for X.
��������������� Offline and virtual candidate
methods differ chiefly in what would be required to metascore them on feasibility�the
degree to which they are likely to generate candidates and assign scores in the
searcher�s circumstances. Roughly, offline candidate methods, being truncated
processes, embody their own test of feasibility; to the degree they are not
feasible, they do not assign scores, even offline. But virtual candidate
methods would need to be metascored using accepted beliefs about
feasibility.
��������������� The statement about offline
methods is �rough� because the operative laws might change upon acceptance of
an offline candidate, perhaps due to meddling demons or angels. And even in the
virtual case beliefs about feasibility would in some way have to rule out (or
otherwise take into account) the possibility of meddling demons and angels.
Since Ren�e is not in a
position initially to measure the likelihood of demons and angels, she is not
in a position initially to measure feasibility of candidate methods. She will
have to find a way to assess methods largely independent of feasibility
considerations. But as her search for truth progresses, if it does at all, she
might come into position to evaluate methods for feasibility.
[12]
There are only these three possibilities for imperfection, because the X-Specs
are not independent. Covering X is a prerequisite for Discriminating X: X does
not get a score at all on the test if it is not generated as a candidate. And
Discriminating X is a prerequisite for Stabilizing on X: X does not remain
accepted (due to a high-enough score) unless it is accepted (due to a
high-enough score).
[13]
It might be suspected that this claim needs to be adjusted depending on the
relative importance of potentially conflicting Specs, but a detailed ordering
of these Specs, relative to their importance in finding X, bears out the
unadjusted claim.
��������������� First compare Coverage to
Discrimination. Since Covering X is a prerequisite for Discriminating X (see
previous note), Coverage inherits whatever value Discrimination has. In
addition, Coverage has some value independent of Discrimination: a method that
Covers X does at least �find� X in a weak sense (by at least generating X for
testing), even if it does not Discriminate X. So X‑Discrimination is less
important than X-Coverage.
��������������� Now compare Discrimination to
Stability. Since Discriminating X is a prerequisite for Stabilizing on X (see
previous note), Discrimination inherits whatever value Stability has. In
addition, Discrimination has some value independent of Stability: a method that
both Covers and Discriminates X does more strongly �find� or �pick out� X, at
least for a brief shining moment, even if it doesn�t stabilize there. So X-Stability
is less important than X‑Discrimination, which is in turn less important
than X-Coverage.
��������������� So ordered from best to worst,
we have methods meeting these groups of Specs:
��������������� Best (3 Specs met): X-Coverage,
X-Discrimination, and X-Stability
��������������� Better (2 Specs met):
X-Coverage, X-Discrimination, but no X-Stability
��������������� Worse (1 Spec met): X-Coverage,
but no X-Discrimination (and so no X-Stability)
��������������� Worst (O Specs met): no
X-Coverage (and so no X-Discrimination, and so no X-Stability)
This ordering bears
out the unadjusted claim: the more Specs a method meets in C the better it is
at finding X in C.
[14]
Since Ren�e�s overall aimings allow for degrees of belief (see note 3), there
may be a second relevant asymmetry between generating and testing. To allow for
degrees of belief, Ren�e needs a test that isn�t necessarily all-or-none, one
that may score a candidate between perfect failure and perfect passing. Since
the maximally inclusive test (�accept all candidate beliefs�) is all‑or‑none,
she cannot make do with it. And since generation of candidates is also
all-or-none�a candidate is either tested or it isn�t�no kind of generation
phase could compensate for the all-or-none nature of the maximally inclusive
test. But, asymmetrically, a suitably gradated test could compensate for the
all-or-none maximally inclusive generation phase (�test all possible candidate
beliefs�).
[15] It might be suggested that if candidates could be ordered in some way (akin to �alphabetizing� them), they could be generated nonrandomly but still one-by-one and nonexclusively. However, such a generation method would be exclusive at each iteration, and if Ren�e�s test relies on such exclusivity this would amount to prejudice, given that she is prepared to accept candidates (provisionally) as she goes, and is poised to use these beliefs in subsequent iterations.
[16]
This assumes she can reach beliefs in such necessary dependence without
prejudice. As in note 7, roughly, she can use other contingencies she can
justifiably believe a priori to be necessitated by (i).
[17] Here is a second argument for the same constraint. Ren�e aims ideally not to discriminate between beliefs with the same content, since these are true or false in the same circumstances. If she relies on semantically irrelevant factors, or factors that are merely contingently semantically relevant, then at best she is lucky (rather than fully epistemically responsible) if despite these factors she treats content‑equivalent beliefs alike. So Ren�e aims ideally to score beliefs by necessarily semantically relevant features, ones that cannot differ between beliefs with the same content.
[18] Further �nonbasic� candidate aims can be formed by truncating and combining the three basic aims: e.g., F raises scores for a certain number of iterations and then lowers (or doesn�t affect) scores thereafter. I ignore these in the rest of this paragraph for illustration�s sake, but Ren�e does have to note them in doing the Two-Step.
[19] Roughly, a concept is basic (for a thinker at a time) if it is distinctively associated with some basic procedure for its use, a procedure whose internal operation does not involve the use of concepts. (�Internal� operation means
[20]
Strictly speaking, Ren�e ought to test these different strands of simplicity
individually as well as in various combinations. But the considerations at Step
Two below work the same for each of the resulting forms of simplicity.
Differences among them do emerge at Step Three below.
�
[21]
Ren�e�s search would stabilize responsibly if she adopts a nonbasic aim of treating complexity as a
virtue only for some specified finite number of iterations, and then halting
her (sub)search. But such an aim would preclude responsible Belief-Coverage.
Either she would be merely lucky if true candidates are generated before the
specified halting point, or she would have to rely on nonexhaustive or
nonexclusive or nonrandom belief generation before the halting point.
[22]
Contrast Ren�e�s epistemic support for simplicity with Harman�s merely
pragmatic defense of �simplicity as ease of use�: �it is rational and
reasonable to ignore hypotheses that are much harder to use in explanation and
prediction than other hypotheses that in other respects account equally well
for the data� (�Rationality�, p. 38). And contrast Ren�e�s unprejudiced support
with Quine and Ullian�s merely contingent �causal connection between subjective
simplicity and objective truth�: �Innate subjective standards of simplicity �
will have survival value insofar as they favor successful prediction. Those who
predict best are likeliest to survive and reproduce their kind, in a state of
nature anyway, and so their innate standards of simplicity are handed down.� (The
Web of Belief, p. 162)
[23]
If Ren�e were as savvy and careful as one student in a class of mine, William
Campbell, she would consider the following problem at this point. SimplicityVirtue counsels convergence toward the
minimal degree of complexity a belief can have (other virtues being equal).
ComplexityVirtue counsels divergence from the minimal degree of complexity.
Now what is the basic reason that SimplicityVirtue beats ComplexityVirtue
as a (responsible) means to Belief-Stability? The crucial difference is
convergence versus divergence in general�it
is not crucial that the convergence/divergence be toward/from the minimal degree of complexity. For any specific degree of complexity n, however large, Convergence-toward-nVirtue would beat
Divergence-from-nVirtue as
a means to Belief-Stability. For any n,
and for any candidate belief, there is always a candidate belief that diverges more from n. So an infinite number of candidate virtues provisionally win in
Step Two�for each degree of complexity n,
Convergence-toward-nVirtue
beats Convergence-toward-nVice.
But each of these provisionally victorious virtues is incompatible with the
rest. Convergence-toward-nVirtue
counsels stabilizing on beliefs nearest complexity n rather than stabilizing on beliefs nearest minimal complexity, or
nearest any other specific degree of complexity. So why should Ren�e accept
Convergence-toward-minimal-complexityVirtue (or in other words,
SimplicityVirtue) instead of Convergence-toward-nonminimal-nVirtue?
[24]
To restrict the commitments to those specifically relevant to the more �narrow�
aspects of content that Ren�e can believe in without prejudice (see note 6),
perhaps the relevant kind of necessary connection between p and the
commitments should not itself depend on further contingencies (see note 7).
[25] Treating parsimony as a virtue is part of Occam�s Razor as originally formulated, but many epistemologists reject Occam�s candidate aim in favor of analogy (sometimes calling this �parsimony� instead). I have never seen an argument for rejecting the� �don�t multiply particular entities� formulation in favor of the �don�t multiply kinds of entity� formulation, but the intuitive motivation often seems to be as follows: given the task of explaining physical observables, for example, most epistemologists favor positing swarms of analogously physical entities (e.g., particles) rather than positing smaller numbers of disanalogous spiritual entities (e.g., a lone malignant demon). On the other hand, the thoughts of the demon are particular entities that must be counted in measuring parsimony, and simplicity alone may be enough to disfavor demonic deception hypotheses (see note 27). Also, a virtue of parsimony counsels that (other virtues being equal) positing fewer demons is preferable to positing more demons even if all the demons are analogous, and counsels that positing fewer particles is preferable to positing more particles even if all the particles are analogous. This result seems unavailable to those who shun parsimony for analogy.
[26]
Contrast Thagard�s merely pragmatic defense of analogy as a theoretical virtue:
�Analogy is a legitimate criterion for inference to the best explanation
because analogies play an important role in improving explanations. We get
increased understanding of one set of phenomena if the kind of explanation used
is similar to ones already used.� (Computational Philosophy of Science,
p. 94)
[27]
Contrast Lycan�s merely pragmatic defense of
conservatism: �Any change of belief � exacts a price, by drawing on energy and
resources. � [C]hanging one�s mind � gratuitously � would be inefficient and
confusing �.� (Judgement and Justification, p. 161) Ren�e sides instead
with Christenson�s dismissal: �If a scientist were to take such considerations
into account, � perhaps she should find out which theory her department chair
wants her to believe, or the dean, or even the provost � [or] Pascal[�s
deity].� (�Conservatism in Epistemology�, p. ???)
[28] By contrast, SimplicityVirtue is supportable even in a testing context in which ConservatismVirtue (alone) is previously accepted. For ConservatismVirtue alone does not give Ren�e a way to change her beliefs, which she needs to do if she is to proceed from her unprejudiced starting point to the whole truth. So Ren�e still needs some other scoring factor, and SimplicityNeutral�s score is lowered, and the situation is otherwise as in Step Two for simplicity.
[29]
For instance, the trouble with demons is that they are far more powerful
than the normally posited physical mechanisms (stable posited entities, stable
perceptual organs, etc.). The normal mechanisms can�t but cause the
candidate beliefs (observables, experiences) that are to be unified
(explained). But demon hypotheses have to be complicated with hypotheses for
each candidate belief: that the demon has a special desire to deceive us via that
particular means instead of some other available means, or that the demon
has a special incapacity to use another means, etc.
[30] I
assume that no evaluative beliefs are among the necessary truths Ren�e is able
to form without prejudice, even if some are necessary truths.
[31]
While this analogy consideration is not available to Ren�e initially, it is
available if she waits to do ethics after she�s done a lot of science. Not that
she has to wait; the aim for analogy allows her to adjust her basic
ethical views in light of her developing scientific views. Similarly, if she
reaches a belief that animals have aims, she reaches a reason to satisfy those
aims. Plants, too (see note 3).
[32] Or at least this is how it all seems, pending some justified way of counting aims. By target, so that multiple aims for the same target count as one? By dependence relations to more basic aims, so that trees of aims count as one? Ren�e should think more about this.