

›› RESEARCH
Big Data: The theoretical foundations of Big Data Science remain a wide open field. We investigate a new Big Data theory for high-throughput analytics and model-free Inference. Specifically, we explore the core principles of distribution-free and model-agnostic methods for scientific inference based on Big Datasets and we call it Compressive Big Data analytics (CBDA).
Data Sharing, Privacy and Utility: Sharing of Big biomedical data, including millions of records with thousands of complex features, provides enormous opportunities for disruptive healthcare innovations. However, the process of data sharing is currently impractical without compromising data value and utility while simultaneously protecting sensitive information. We are proposing a multidisciplinary approach to develop a novel statistical technique (DataSifter) that solves this data-sharing challenge.
Systems Biology: mathematical modeling of immune response to pathogens (mathematical modeling of Mycobacterium tuberculosis) and host-microbiome interactions. Infection data are are from human, primate and mouse.
Mathematics: representing cell populations dynamics and interaction by various mathematical modeling techniques, e.g. deterministic Ordinary Differential Equation (ODE) and Delay Diffferential Equation (DDE) systems, as well as Stochastic models (Agent Based Models– ABM)).
Statistics: Parameter estimation and statistical techniques for uncertainty and sensitivity analysys in complex mathematical models (for example, statistical and computational techniques are used to model the effect of antigen dose on the early events in the immune response during Mycobacterium tuberculosis infection).
Bioinformatics: Data Mining and Biochemical System Network discovery
›› My updated CV
›› My Google Scholar Metrics and Publication List
›› WHO I AM
EDUCATION/TRAINING
• University of Rome I "La Sapienza", Rome, Italy. B.S. and M.S. (1997). Applied Statistics
• Ph.D.. University of Rome I "La Sapienza", Rome, Italy. 2002. Operations Research. Mentor: Angrea De Gaetano, MD PhD
• Postdoctoral Fellowship. University of Michigan Medical School, Dept. Microbiology and Immunology, Ann Arbor, MI. 2002-2005. Biomathematics. Mentor: Denise Kirschner PhD
• Postdoctoral Fellowship. Medical University of South Carolina, Charleston, SC. 2004. Bioinformatics. Mentor: Eberhard Voit PhD
POSITIONS
• Feb-June 2004, Postdoctoral Fellow, Biostatistics, Bioinformatics and Epidemiology, MUSC, Charleston, SC
• 2002-2005, Research Fellow, Microbiology and Immunology, University of Michigan, Ann Arbor, MI
• Jan-July 2005, Research Faculty, The Wallace H. Coulter Department of Biomedical Engineering at Georgia Tech and Emory University, Atlanta, GA
• July 2005-2011, Research Investigator, Microbiology and Immunology, University of Michigan, Ann Arbor, MI
• Sept 2011-2018, Research Assistant Scientist, Microbiology and Immunology, University of Michigan, Ann Arbor, MI
• June 2018-present, Research Associate Scientist, Microbiology and Immunology, University of Michigan, Ann Arbor, MI
• Sept 2016-present, Research Computer Specialist, School of Nursing - SOCR, University of Michigan, Ann Arbor, MI
BIO
I have a joint appointment as Research Associate Scientist in the Department of Microbiology and Immunology at the University of Michigan Medical School and a Research Computer Specialist position at the School of Nursing. Rome (Italy) is my beloved hometown, where I was born on June the 1st 1970. I spent the first 30 years of my life there and then in 2001 I decided to move to the United States to pursue my dreams and do science. I have a unique multi-disciplinary background, spanning from statistics and probability, to operations research, mathematics and systems biology. I have always tried to combine all these assets and skills throughout my research career, starting from my PhD thesis.
I got both a MS in Statistics (May 1997) and a PhD in Operations Research (Dec 2001) at the University of Rome "La Sapienza", Dept. of Statistic, Probability and Applied Statistic). I got my PhD in Operations Research at the Biomathematics Laboratory of the National Research Council, in Rome: it is located in the "Gemelli" area, which comprises the hospital (it's the hospital of the Pope), the university and many research facilities and institutions.
My PhD dissertation was based on parameter estimation of Ordinary Differential Equations (ODEs) systems by Least Squares (LS) approach and nonlinear programming algorithms. It merges both statistics and operations research, as well as biomathematics: in fact the mathematical models implemented in my PhD are related to glucose-insulin and lipids dynamics, including many simulations of growth and decay curves (Gompertz, Logistic, ....). Since then, I have been interested in biology and fascinated by immunology, which to me represents the perfect example of a continuously evolving complex system. Since then, I also proudly call myself a systems biologist.
I moved to Ann Arbor in July 2001 as a Research Fellow in Denise Kirschner lab, where I studied immunology for the first time in my life. Denise opened my mind to the wonderful world of immune system: it looked, and still looks, like sci fi to me. It's really amazing. My main research was on building mathematical models of the many faces of immune response to Mycobacterium tuberculosis infection in human.
Why TB? Well, my grandfather died of tuberculosis and I found out that the TB global burden is still enormous today: TB is the world's leading cause of death in humans from a single infectious agent, with a newly infected individual every second and approximately 35 deaths every 10 minutes (~2 million a year). I also realized that mathematical and computational modeling approaches can provide a unique opportunity to identify factors that are crucial to a successful outcome of infection in humans. These modeling tools not only offer an additional avenue for exploring immune dynamics at multiple biological scales, but also complement and extend knowledge gained via experimental tools. This gave me extra motivation and my research since then and for the past 10 years has mainly focused on questions related to host-pathogen interactions in infectious diseases, with a specific interest in the host immune response to Mtb at multiple spatial and time scales. All of these studies have been funded by the National Institutes of Health, through grants awarded to Dr. Kirschner, with myself as co-PI.
I moved to the Department of Biostatistics, Bioinformatics and Epidemiology at MUSC (Charleston, SC) for a short time in 2004, and later I joined the Department of Biomedical Engineering at Georgia Tech and Emory University in Atlanta. In both departments, I worked as a Research Scientist with Eberhard Voit on metabolic pathway network discovery (based on S-Systems approach, power-law formalism and biochemical system theory), applying algorhytms developed during my PhD years. I used non linear least squares as data fitting scheme for extracting structural information from time series of metabolite concentrations, or of gene or protein expression profiles. Biochemical system theory (BST) is the theoretical modeling framework, but the approach can be applied to general nonlinear systems of differential equations.
I then moved back to Ann Arbor in July 2005 as a faculty (Research Investigator) and being promoted to Assistant and most recently to Associate Research Scientist (2018).
I now mostly work on Data Science and Big Data Analytics in the SOCR - Statistical Online Computational Resources group, led by Prof Ivo Dinov. My research interests spans from machine learning to develop methodologies and protocols for handling and sharing Big Data.
COMPRESSIVE BIG DATA ANALYTICS -CBDA
The theoretical foundations of Big Data Science are not fully developed, yet. The CBDA project investigates a new Big Data theory for high-throughput analytics and model-free Inference. Specifically, we explore the core principles of distribution-free and model-agnostic methods for scientific inference based on Big Data sets. Compressive Big Data analytics (CBDA) represents an idea that iteratively generates random (sub)samples from the Big Data collection, uses a collection of established techniques to develop model-based or non-parametric inference, repeats the (re)sampling and inference steps many times, and finally uses bootstrapping techniques to quantify probabilities, estimate likelihoods, or assess accuracy of findings. The CBDA approach may provide a scalable solution avoiding some of the Big Data management and analytics challenges. CBDA sampling is conducted on the data-element level, not on the case level, and the sampled values are not necessarily consistent across all data elements (e.g., high-throughput random sampling from cases and variables within cases). An alternative approach is to use Bayesian methods to investigate the theoretical properties (e.g., asymptotics, as sample sizes increase to infinity, but the data has sparse conditions) of model-free inference entirely based on the complete dataset without any parametric or model-limited restrictions. Specific applications include neuroimaging-genetics studies of Alzheimer’s disease, predictive modeling of cancer treatment outcomes, and high-throughput data analytics using graphical pipeline workflows.

DATA SIFTER - Statistical Obfuscation of Sensitive Big Data enabling Advanced Information Aggregation, Sharing, and Analytics
There are no practical, scientifically reliable, and effective mechanisms to share real clinical data containing clearly identifiable personal health information (PHI) without compromising either the value of the data (by excessively scrambling/encoding the information) or by introducing a substantial risk for re-identification of individuals (by various stratification techniques). The DataSifter represents a novel method and a computational protocol for on-the-fly de-identification of sensitive information, e.g., structured Clinical/Epic/PHI data. This approach provides a complete administrative control over the risk for data identification when sharing large clinical cohort-based medical data. At the extremes, a data-governor may specify that either synthetic data or completely identifiable data is generated and shared with the data-requester. This decision may be based on data-governor determined criteria about access level, research needs, etc. For instance, to stimulate innovative pilot studies, the data office may dial up the level of protection (which may naturally devalue the information content in the data). On the other hand, for more established and trusted investigators, the data governors may provide a more egalitarian dataset that balances preservation of information content (data-energy or analytical-value) and security (protection of sensitive-information). In a nutshell, responding to requests by researchers interested in examining specific healthcare, biomedical, or translational characteristics of multivariate clinical data, the DataSifter allows data governors, like Healthcare Systems, to filler, export, package, and share sensitive clinical and medical data for large population cohorts.The DataSifter may provide the critical infrastructure at the right time to enable secure transdisciplinary team-based interrogation of Big Data including sensitive information. This unique functionality is necessary in many active R&D-intense organizations and high-tech companies!
HOST-MICROBIOME WORK
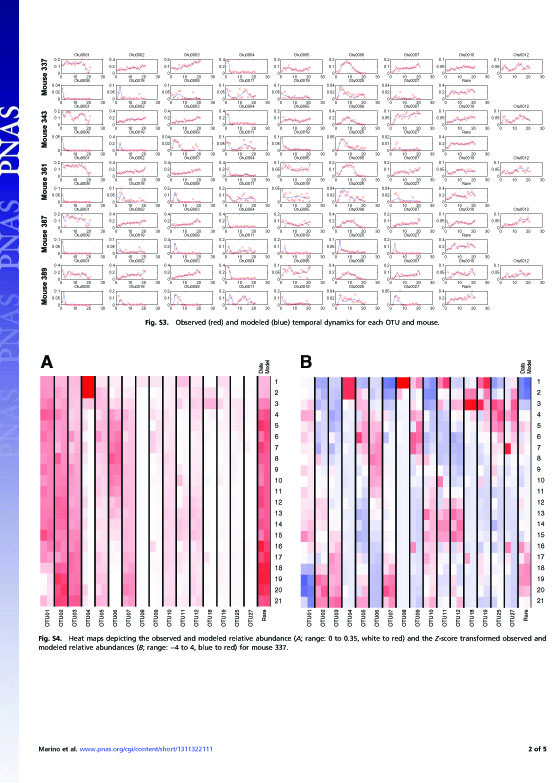
Based on the work with Eberhard Voit, I have recently devoted part of my research efforts on algorithms for data-driven model generation, fitting and selection (GFS algorithm, i.e., network inference) of gut microbiome data. I am currently working as a co-PI with Dr. Pat Schloss here at the University of Michigan (NIH RO1 grant funded) on Operational Taxonomic Units (OTU) microbiome data. The goal of this research project is to develop a dynamical model (ODE) that identifies, quantifies and predicts the overall architecture and dynamics of mice OTU data (relative abundance of microbial communities). This work will set the foundations for a more systematic and comprehensive study of host-microbiome interactions, where the effects of antibiotics is investigated in the context of microbiome diversity and stability, as well as susceptibility to bacterial (for example Clostridium difficile infection-, or CDI) or viral infections.

UNCERTAINTY AND SENSITIVITY ANALYSIS
A recurring central theme across all these modeling efforts is to choose how to perform network inference, parameter estimation and model validation. Accurate estimation of model parameters and ultimately the strength and quality of model predictions are challenged by an intrinsic biological and experimental variability in rates measured from in vivo or in vitro studies, where some interactions in the systems are not even currently measurable. As system biologists, we quantify the importance of each host mechanism involved directly and indirectly in the infection dynamics using statistical techniques known as uncertainty and sensitivity analyses. I recently published a highly cited review in Journal of Theoretical Biology which represents the first systematic study on uncertainty and sensitivity analyses techniques, focused on systems biology applications. The approach can be generalized to any type of model in which parameters are unknown/uncertain: discrete and continuos, deterministic/stochastic. Statistical sampling techniques (uncertainty) and generalized correlation indexes and variance decomposition methods (sensitivity) when combined guide our understanding as to how and what extent variability in parameter values affects infection outcomes. This approach can be used in a variety of mathematical and computational model settings and should be a necessary step for model validation, in any field, and especially needed in systems biology and complex systems. Some of these techniques are explicitly developed for deterministic models. However, we showed how they can be extended to stochastic models, such as agent-based models. Moreover, large complex systems can use uncertainty and sensitivity analyses techniques as a viable alternative for model fitting. A similar challenge is to apply classical model fitting approaches to ABM systems, where not only time courses need to be matched, but also shapes and patterns emerging from the model simulations. I plan to address most of the above questions in my future research.
HOBBIES
SOCCER: being italian (US citizen now) and married to a Costarican , I love soccer and I coach kids K-12 in the Ypsilanti Twp recreation Program. My national team is Italy of course, but AS Roma has a special place in my heart.
MUSIC: I love music, both listening (particularly jazz) and playing (piano). I used to play jazz, R&B and soul in many bands in Italy.
›› CONTACT ME
If you want to share some thoughts, drop me a line at simeonem@gmail.com .
Albert Einstein
If we knew what it was we were doing, it would not be called research, would it?