One-shot/static data mixing
Given:
-
$M$ data sources/types $D_1,\dots,D_M$ (eg chat logs, code, scientific papers etc)
-
$K$ (loss) metrics $L_1,\dots,L_K$ (eg benchmarks) (often $K = M$)
-
training algorithm $\cA$ that maps data mixes $\pi\in\Delta^{M-1}$ to models $\cF$ (eg loss minimization on IID samples from $\sum_{m=1}^M\pi_mP_m$)
the optimal one-shot/static data mixing problem is
$$\textstyle \min_{\pi\in\Delta^{M-1}}(L_1(\cA[\pi]),\dots,L_K(\cA[\pi])). $$Ex: Inclusive Images Competition

-
$D_k$ consists of images from the $k$-th geographic area
-
$L_k$ are (classifier) accuracies on images in $D_k$ ($K = M$ here)
-
$\cA[\pi]$ is loss minimization on samples from $\sum_{m=1}^M\pi_mP_m$
Dynamic data mixing
The training algorithm $\cA$ maps sequences of data mixes
$$ \pi_{1:T}\triangleq(\pi_1,\dots,\pi_T),\quad\pi_t\in\Delta^{M-1} $$to models $\cF$ (eg curriculum learning
$$\textstyle f_{t+1}\gets\argmin_{f\in\cF}\sum_{m=1}^M\pi_mE_m(f) + D(f,f_t) $$where $E_m$ is the training error on the $m$-th data type and $D$ is a proximity term).
The optimal dynamic data mixing problem is
$$ \begin{aligned} &\min\nolimits_{\pi_{1:T}}&&(L_1(\cA[\pi]),\dots,L_K(\cA[\pi])) \\ &\subjectto&&\{\pi_t\in\Delta^{M-1}\}_{t=1}^T. \end{aligned} $$Ex: LLM pretraining
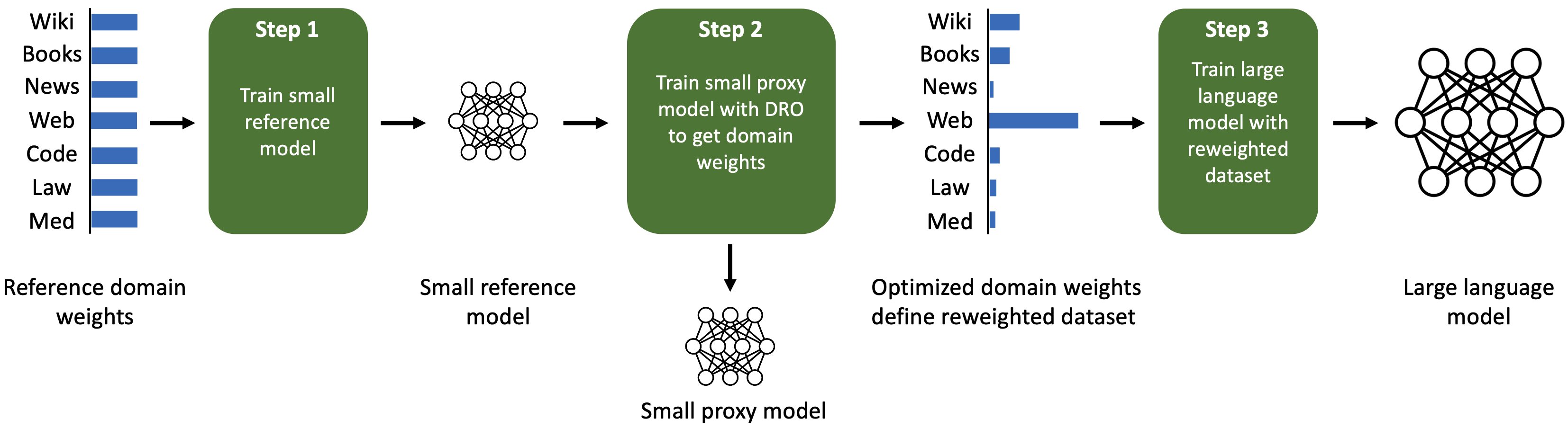
Data mixing laws
Goal: anticipate cross data-type effects during training
$$\textstyle L_m^{(t+1)}(\pi_t) \triangleq L_m^{(t)} + \sum_{m,n}A_{m,n}^{(t)}(\pi_t)_n \tag{DML} $$-
DoReMi: $A_{m,n}^{(t)} = \max\{0,L_m^{(t)} - L_m(f_\text{ref})\}$
-
DoGE: $A_{m,n}^{(t)} = \nabla L_m^{(t)}(\pi_{t-1})^\top\nabla L_n^{(t)}(\pi_{t-1})$
-
Skill-It: $A$ is the (weighted) adjacency matrix of a "skills graph"
-
Aioli and Ye et al fit (more general versions of) (DML) to data from previous training runs.