|
|
Topics
Semi-supervised NMF for Homogeneous Data Clustering
|
Problem
Definition
-
Semi-supervised clustering uses class labels or
pairwise constraints on data objects to aid
unsupervised clustering. It can group data using the
categories of the initial labeled data as well as
unlabeled data in order to modify the existing set
of categories which reflect the whole regularities
in the data.
Algorithms
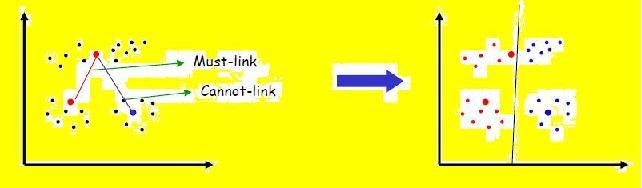
- Supervision is provided as two sets of pairwise
constraints on the data objects: must-link
constraints M and cannot-link constraints C. Every
pair of data (x_i, x_j) in M implies that xi and xj
must belong to the same cluster. Similarly, all
possible pairs (x_i, x_j) in C implies that the two
objects should belong to different clusters (see
above Figure).
- Perform symmetric non-negative tri-factorization
of the data similarity matrix A with constraints using
an interative algorithm to minimize |A- GSG|^{2}, where
G is a cluster indicator matrix, and S is a cluster centroid matrix.
The correctness and
convergence of the algorithm are proved by showing
that the solution satisfied the KKT optimality and
the algorithm is guaranteed to converge.
Results
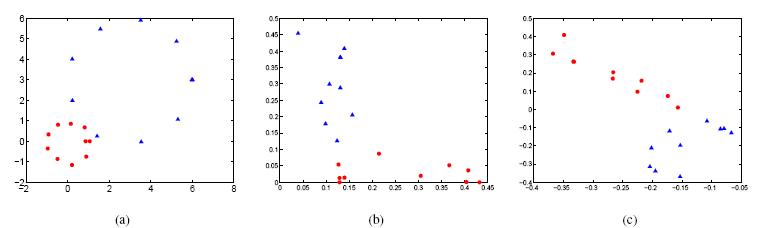
- In the following figures, (a) shows an artificial
toy data set consisting of two natural clusters, (b)
shows data distribution in the SS-NMF subspace of
the two column vectors of indicator G. The data
points from the two clusters get distributed along
the two axes, and (c) shows data distribution in the
SS-SNC subspace of the first two singular vectors.
There is no relationship between the axes and the
clusters.
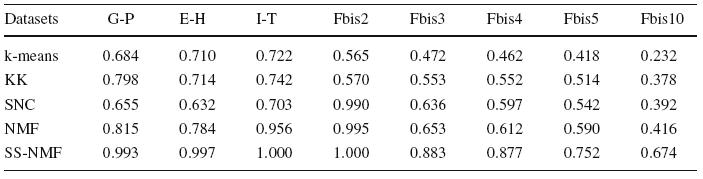
- In the following table, we compared the algorithms on
some document datasets using AC values. The performance of
the first three methods is similar with NMF proving to be
the best amongst the unsupervised methods. However, the
accuracy of NMF greatly deteriorates and is unable to
produce meaningful results on datasets having more than two
clusters. On the other hand, the superior performance of
SS-NMF is evident across all the datasets. We can see that
in general a semi-supervised method can greatly enhance the
document clustering results by benefiting from the user
provided knowledge.Moreover, SS-NMF is able to generate
significantly better results by quickly learning from the
few pairwise constraints provided.
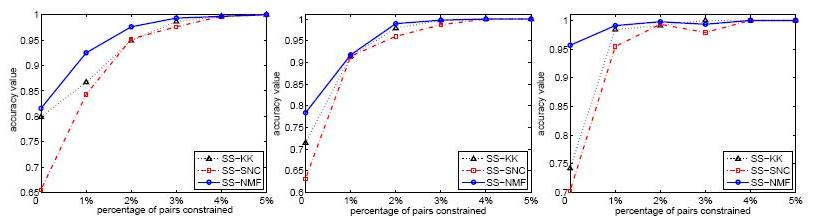
- The following sub-figures show that the AC values
against increasing percentage of pairwise
constraints available, for the algorithms on some
document datasets. On the whole, all three
algorithms perform better as the percentage of
pairwise constraints increases. Comparatively,
SS-NMF gets better accuracy than the other two
algorithms even for minimum percentage of pairwise
constraints.
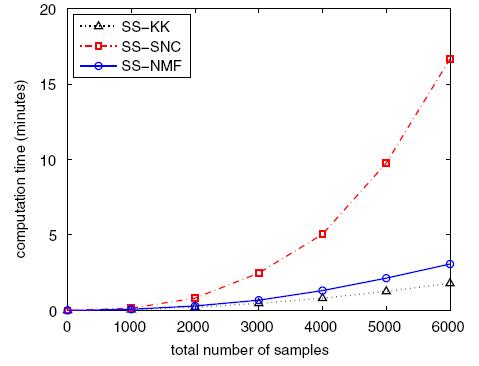
- We plotted the computational speed of SS-NMF with respect to SS-KK and
SS-SNC in the following figure. As the number of data samples increase, SS-SNC
turns out to be the slowest of the three algorithms. SS-KK is the quickest with
SS-NMF closely following it. SS-NMF provides an efficient approach for
clustering.
Related Publications
- Yanhua Chen, Manjeet Rege, Ming Dong and Jing Hua,
"Non-negative Matrix Factorization for
Semi-supervised Data Clustering", Journal of
Knowledge and Information Systems (Springer), Vol.
17, No. 3, pp. 355 - 379, 2008. (invited as a best
paper of ICDM 07, conference version: "Incorporating
User provided Constraints into Document Clustering",
was published in Proc. of IEEE International
Conference on Data Mining, Omaha, NE, 2007 as a
Regular paper, acceptance rate 7.2%).
- Yanhua Chen, Manjeet Rege, Ming Dong and Farshad
Fotouhi, "Deriving Semantics for Image Clustering
from Accumulated User Feedbacks", Proc. of ACM
Multimedia, Germany, 2007 (acceptance rate: 24%).
|
|
| |