|
|
|
I. Postdoc Research Summary
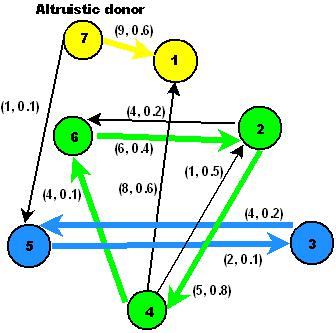
More than 150,000 individuals in the USA are living with a kidney transplant. There are a long waiting list:
82,966 patients on the list as of January 23, 2010, and in 2009, there were 28,381 patients have been added to
the list, while only 14,060 patients have been luckily received the transplant kidneys. Deceased donation and living
donations are the two resources of organs for transplantation, and living-donor transplant has a higher chance of
success. However, often times willing donors (even within the same family) are incompatible with recipients due
to various biological factors, such as ABO blood type mismatch and human leukocyte antigen (HLA) mismatch.
The National Kidney Paired Donation (KPD) transplants program has been established as a novel clinical solution
to overcome the shortage of donors. The essential idea of the KPD program is to exchange living kidney donors
between two recipient/donor pairs. The fundamental question in the KPD program is how to make an optimal
decision of organ exchanges that benefit patients the best.
We propose to take a graph-based approach, Optimal Graph Crossmatch
Model (OGCM), for the KPD program to provide innovative statistical
tools to design clinical studies and to analyze data from clinical studies,
and hence improving patients’ well-being as well as quality of life. OGCM
will enhance existing algorithms to analyze
both static and dynamic large graphs to identify all compatible matches
between any number recipient/donor pairs, leveraging the efficiency of graph
matching strategy and the optimization of maximum number and quality of
transplants. The goal of the project is to integrate high-level user interactivity
into OGCM through software and real-time computing to find the set of
mutually exclusive kidney exchanges that achieves the maximum number of
transplants offering the highest quality transplants.
|
External Projects
SOFTWARE/CODE AND DATA
|
II. PhD Research Summary
Generally, data mining (sometimes called data or knowledge discovery) is the process
of analyzing data from different perspectives and summarizing it into useful information - information that can be used to increase revenue, cuts costs, or both.
The most commonly tasks in data mining include: classification, clustering, visualization, estimation and so on.
Clustering or unsupervised learning is a generic name for a variety
of procedures designed to find natural groupings or clusters in
multidimensional data based on measured or perceived similarities
among the patterns. The purpose of clustering is to extract useful information
from unlabeled data, and it plays a very important role in data mining.
Moreover, with the fast growth of Internet and computational technologies in
the past decade, many data mining applications have advanced swiftly
from the simple clustering of one data type to the co-clustering of
multiple data types, usually involving high heterogeneity. Applications of data
clustering/co-clustering are found in many fields, such as
information discovery, text mining, web analysis, image grouping,
medical diagnosis, and bioinformatics.
In many practical learning domains (e.g., text processing,
bioinformatics), there is a large supply of unlabeled data but
limited labeled data, and in most cases it might be expensive to
generate large amounts of labeled data. Traditional
clustering/co-clustering algorithms completely ignore these valuable
labeled data and thus are inapplicable to these problems.
Consequently, semi-supervised clustering, which can incorporate the
domain knowledge to guide a clustering algorithm, has become a topic
of significant recent interest. We first develop a Non-negative Matrix
Factorization (NMF) based framework to incorporate prior knowledge
into data clustering. Later, we extend
SS-NMF to do heterogeneous data co-clustering.
From a theoretical perspective, SS-NMF for data clustering/co-clustering
is mathematically rigorous. The
convergence and correctness of our algorithms are proved. In addition, we show that
our work provides a unified view for data clustering/co-clustering. Some well-established
approaches can be considered as special cases or variations of our
models. Experiments performed on various publicly available data
sets demonstrate the superior performance of our work.
On the other hand, we further propose a novel model for exemplar-based clustering.
Exemplar-based clustering is to find the representative "exemplars" from the actual data points
and simultaneously cluster them into meaningful groups characterized
by exemplars. Instead of "centroids" derived from the traditional
clustering, exemplars are more useful since they enable us to better
summarize and visualize the data.
|
External Projects
SOFTWARE/CODE AND DATA
Topics
-
Semi-supervised NMF for Homogeneous Data
Clustering
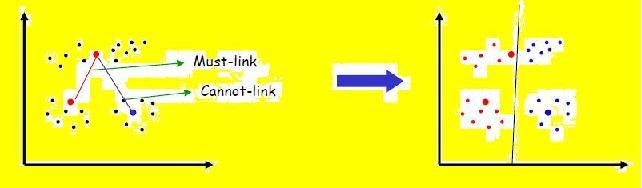
Traditional clustering algorithms are inapplicable to many
real-world problems where limited knowledge from domain experts is
available. Incorporating the domain knowledge can guide a clustering
algorithm, consequently improving the quality of clustering. We
propose SS-NMF: a semi-supervised non-negative matrix factorization
framework for data clustering. In SS-NMF, users are able to provide
supervision for clustering in terms of pairwise constraints on a few
data objects specifying whether they "must" or "cannot" be clustered
together. Through an iterative algorithm, we perform symmetric
trifactorization of the data similarity matrix to infer the
clusters. Theoretically, we show the correctness and convergence of
SS-NMF and SS-NMF provides a general framework for semi-supervised
clustering. Through extensive experiments conducted on publicly
available datasets, we demonstrate the superior performance of
SS-NMF for clustering. Further details of this work are
available here.
|
-
Semi-supervised NMF for Heterogeneous
Data Co-clustering
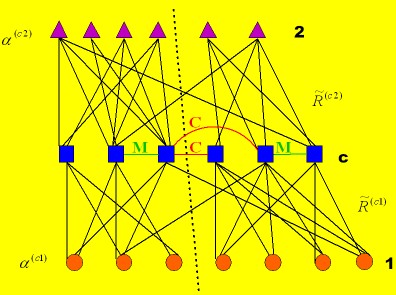
Co-clustering heterogeneous data has attracted extensive attentions
recently due to its high impact on various important applications,
such us text mining, image retrieval and bioinformatics. However,
data co-clustering without any prior knowledge or background
information is still a challenging problem. We propose a
Semi-Supervised Non-negative Matrix Factorization (SS-NMF) framework
for data co-clustering. Our method computes a new pairwise
relational matrix by incorporating user provided constraints through
distance metric learning. Using an iterative algorithm, we perform
tri-factorization of the new matrix to infer the clusters of two
data types. Through extensive experiments conducted on publicly
available data sets, we demonstrate the superior performance of
SS-NMF for data co-clustering. Further details of this work
are available here.
|
- Exemlpar-based Visualization of Large Document Corpus
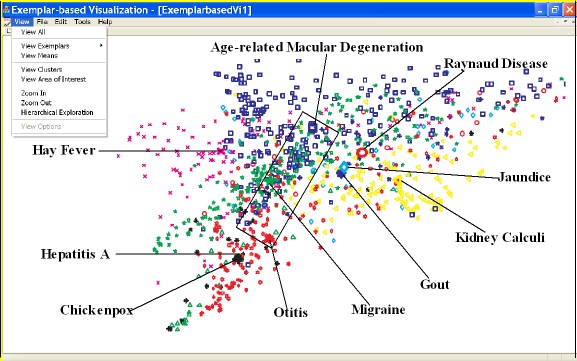
With the rapid growth of the World Wide Web and electronic information services,
many data, such as text corpus, bioinformatics, and so on, are becoming available on-line at an incredible rate.
By displaying them in a logical layout (e.g., color graphs),
data visualization presents a direct way to observe the data
as well as understand the relationship between them.
In this work, we propose a novel technique, Exemplar-based Visualization (EV), to visualize
an extremely large data sets.
Capitalizing on recent advances in matrix
approximation and decomposition, EV presents a probabilistic multidimensional projection model
in the low-rank data subspace with a sound objective function. The probability of each data sample proportion to
the class is obtained through iterative optimization and
embedded to a low dimensional space using parameter embedding.
By selecting the representative exemplars, we obtain a compact
approximation of the data. This makes the visualization highly efficient and flexible. In addition, the selected exemplars neatly
summarize the entire data set and greatly reduce the cognitive
overload in the visualization, leading to an easier interpretation of
large data sets. Empirically, we demonstrate the superior performance of EV
through extensive experiments performed on the publicly available data sets.
Further details of this work are available
here.
|
| |