|
|
Topics
Semi-supervised NMF for Heterogeneous Data Co-clustering
|
Problem
Definition
-
With the fast growth of Internet and computational technologies in
the past decade, many data mining applications have advanced swiftly
from the simple clustering of one data type to the co-clustering of multiple
data types, usually involving high heterogeneity. Generally, co-clustering can be divided into two types:
pairwise co-clustering (i.e., two types of heterogeneous data clustering) and
high-order co-clustering (i.e., multiple types of heterogeneous data). For example, the
interrelations of words, documents and categories in text corpus,
Web pages, search queries and Web users in a Web search system,
papers, keywords, authors and conferences in a scientific
publication domain can be identified through simultaneous
clustering of several related data types. Through
co-clustering, we are able to discover a hidden global structure in
the heterogeneous data, which seamlessly integrates multiple
data types to provide us a better picture of the underlying
data distribution, highly valuable in many real world applications.
However, accurately co-clustering heterogeneous data without domain-dependent
background information is still a challenging task. In our model, given a Star-structured Heterogeneous Relational Data (SHRD) set,
with a central data type X_c, and l feature
modalities X_1, ..., X_p, ..., X_l, the goal is to cluster central data type
X_c into k_c disjoint clusters simultaneously with
feature modality X_1 into k_1 disjoint clusters,
..., X_p into k_p disjoint clusters, ... , and X_l into k_l disjoint clusters.
Notice that SHRD provides a very good abstraction for many real-world data mining
problems. For example, it can be used to model words, documents and
categories in text mining, where the document is the central data
type; authors, conferences, papers and keywords in academic
publications, where the paper is the central data type;
and images, color, and texture features in image retrieval, where the image is
the central data type.
 |
Algorithms
- We first model SHRD using a set of relation
matrices. That is, a matrix R^{(cp)} is used to represent the relation between a central data
type X_c and a feature modality X_p.
- The supervision is provided
as two sets of pairwise constraints derived from the given labels on the
central data type: must-link constraints M
(x_i,x_j) and cannot-link constraints C = (x_i,x_j), where
(x_i,x_j) in M implies that x_i and x_j are labeled as belonging to the
same cluster, while (x_i,x_j) in C implies that (x_i, x_j) are labeled as
belonging to different clusters. Note that our assumption is made
based on the fact that in practice constraints are much easier to specify on the central data type
(e.g., documents in document-word co-clustering) than on the feature modalities (e.g., words).
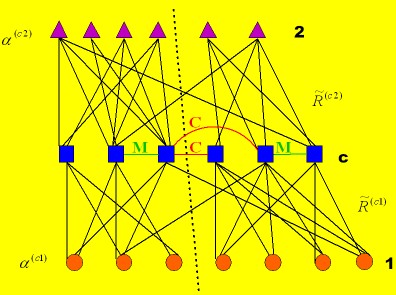
The above figure shows a data triplet, the basic element of SHRD, with
constraints on the central data type. The green edges indicate the
must-link constraints M, while the red edges
denote the cannot-link constraints C. The dotted line
shows the optimal co-clustering result.
- Through distance metric learning and modality selection (i.e., feature weight "alpha"),
prior knowledge is integrated into co-clustering, making
must-link central data points as tight as possible and cannot-link central data points as loose as possible.
- Using an iterative algorithm, we then perform
tri-factorizations of the new data matrices, obtained with the
learned distance metric, to infer the central data clusters while
simultaneously deriving the clusters of related feature modalities.
Results
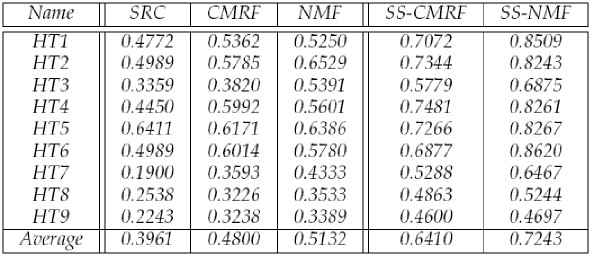
- In the following table, we compared the algorithms on co-clustering
some document datasets using AC values. It shows document co-clustering accuracy obtained by
SRC, CMRF, NMF, SS-CMRF and SS-NMF (both with 15% constraints). Averaged AC values over all nine data
sets are also reported. It is obvious that NMF outperforms
other unsupervised methods in six out of nine data
sets. In general, SRC performs the worst amongst the
three unsupervised ones. Specifically, its accuracy on the
data set HT7 is only 19%. Also from the table, semi-supervised
methods provide significantly better results than the
corresponding unsupervised ones. The average AC of
SS-CMRF increases 15% over CMRF, while up to 20% is
gained by SS-NMF over NMF. We also observe that SS-NMF
can achieve high clustering accuracy (over 80%)
in five out of the nine data sets. The average AC of SS-NMF
is 72.43%, about 10% higher than that of SS-CMRF.
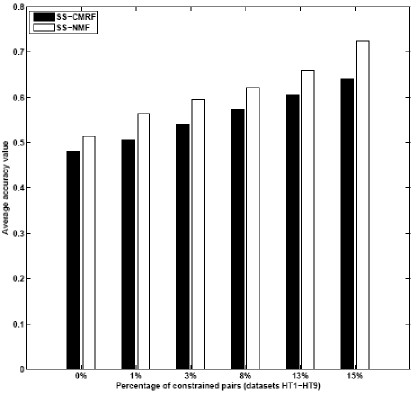
- The following figure shows
that the average AC values against
increasing percentage of pairwise constraints for SS-CMRF
and SS-NMF. Again, when more prior knowledge
is available, the performance of SS-CMRF and SS-NMF
clearly gets better. It is also obvious that on average
SS-CMRF is consistently outperformed by SS-NMF with
varying amounts of constraints.
 |
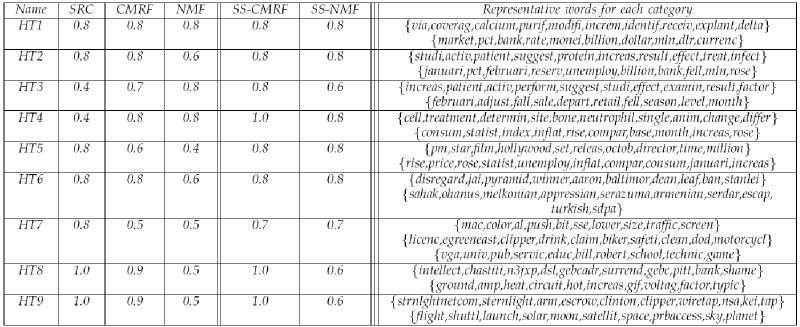
- We report the accuracy
of text categorization by SRC, CMRF, NMF, SS-CMRF
and SS-NMF in the left panel of the following table.
In six out of nine text data sets, the AC
value of SS-NMF either ranks the best or the second with
exceptions on the data sets: HT3, HT8 and HT9.
In high-order co-clustering, we also obtain the clusters
of words simultaneously with the clusters of documents
and categories. However, for text representation, there
is no ground truth available to compute an AC value.
Here, we select the "top" 10 words based on mutual
information for each word cluster associated with a
category cluster and list them in the right panel of the table.
These words can be used to represent the underlying
"concept" of the corresponding category cluster.
 |
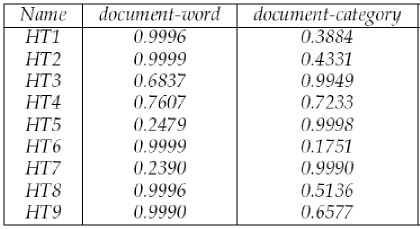
- The very important result is about modality selection.
First, modality selection can provide additional
information on the relative importance of various
relations (e.g., "word" and "category") for grouping the
central data type (e.g., "document"). Moreover, from a
technical point of view, it also acts like feature selection
when computing the new relational data matrix. The following table
lists the modality importance for the
two relations: document-word and document-category in SSNMF
with 1% constraints. A higher value in the table
indicates more importance. It is clear that the significance
of "word" and "category" are quite different in different
data sets.
 |
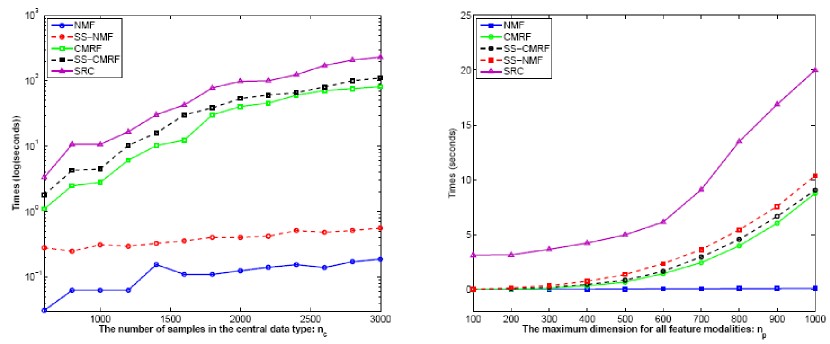
- We compare the computational speed of three
unsupervised approaches: SRC, CMRF, and NMF, and
two semi-supervised approaches: SS-CMRF and SS-NMF in the following figures.
In both cases, unsupervised NMF is the quickest
among the five approaches as it uses an efficient iterative
algorithm to compute the cluster indicator and
cluster association matrices. SS-NMF ranks second as n_c
increases while close to CMRF and SS-CMRF when n_p
increases. The difference between SS-NMF and unsupervised
NMF is mainly due to the additional computation
required to learn the new distance metric,
in which we need to solve a generalized eigenproblem.
We observe that in the following left figure, the computing
time for SS-NMF is close to unsupervised NMF because
both methods have a linear complexity of n_c when n_p
is fixed. On the other hand, as shown in the following right figure,
time for SS-NMF increases more quickly when
n_c is fixed. In addition, the speed of CMRF and SS-CMRF
is between NMF and SRC. The computing time
of these two algorithms increases quickly in both cases
since their complexity is the third power of n_c or n_p when
the other is fixed. Moreover, we observe that SRC is
the slowest in both cases. Even though SRC is completely
unsupervised, it needs to solve a computationally
more expensive constrained eigen-decomposition problem
and requires additional post-processing (k-means) to
infer the clusters. From these results, it is obvious that
SS-NMF provides an efficient way for semi-supervised
data co-clustering.
 |
Related Publications
- Yanhua Chen, Lijun Wang, and Ming Dong,
"Non-negative Matrix Factorization for Semi-supervised
Data Co-clustering", IEEE Transactions on Knowledge and Data Engineering (TKDE), Vol. 22, No. 10, pp. 1459-1474, October 2010.
- Yanhua Chen, Lijun Wang, and Ming Dong, "
Semi-supervised Document Clustering with Simultaneous Text Representation and Categorization",
accepted by European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD),
appear in the Proceedings of Springer-Verlag Lecture Notes in Artificial Intelligence (LNAI), Bled, Slovenia, 2009 (acceptance rate: 22%).
- Yanhua Chen, Ming Dong, and Wanggen Wan, "
Image Co-clustering with Multi-modality Features and User Feedbacks",
accepted for publication by ACM International Conference on Multimedia (ACM MM), Beijing, China, 2009 (acceptance rate = 28%)
|
|
| |